Loglab Introduction
What Is Loglab
Loglab is an analyzer of system/app logs. Unlike most of the log anomaly detection techniques, it does multi-classification of issues to help us understand what’s wrong with the system/app. See the implementation at LogAnalyzer.
It is based on log template as Loglizer and DeepLog are.

The Problem We Want To Resolve
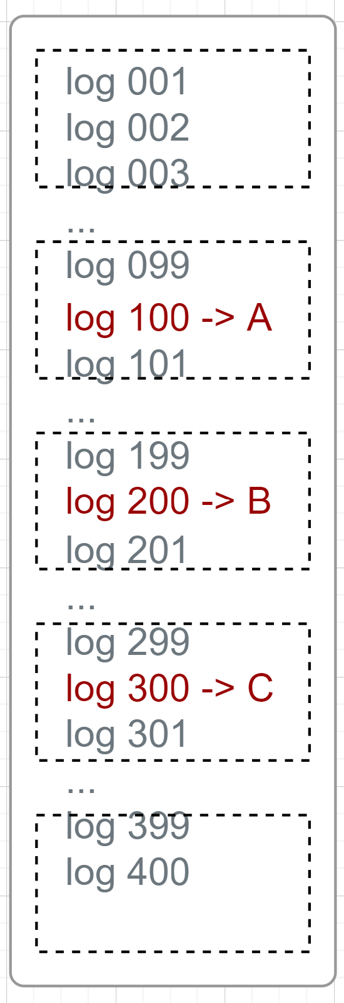
Suppose log keys A/B/C are abnormal. The A+B+C in a sequence / combination (maybe together with its window contexts) represents a class of failure case.
Can we directly increase the window size to cover the A+B+C in one big window in anomaly detection? No (actually it depends on the model selected.). Anomaly detection (ADet) needs all logs get involved in the computation of training and prediction. In other words, a lot of normal logs are used in ADet, but these logs may not appear in all training and prediction logs.
We only need the anomalies and its contexts to decide what the issue is.
Selection of Anomaly Detection
To cherry pick the anomalies throughout all the logs, three options, aka. Loglizer, DeepLog and OSS (Old School System, aka. knowledge-base). Loglizer and DeepLog don’t require domain knowledge except labelling of the former one. Sounds good, but maybe not practical. Anyway, periodical retraining of anomaly detection models cannot be avoidable.
OSS is more practical. Hardly produces false positive. Has strong noise tolerance. No need train any models but just add new typical templates to knowledge base. Another advantage is parameter anomalies are considered in OSS.
Selection of Model: Deep Learning / LSTM or Classical Machine Learning
LSTM takes care of the word order in the sequence {a -> A -> b -> c -> B -> d -> e -> C -> f} -> class 001.
While multi threads / interrupts will break the sequence. Some contexts around anomalies are not sequential in nature. Consider attention mechanism? Need huge training logs.
For logs of prediction, it’s not feasible to indicate where the sequence should start from / end. We have the same issues as DeepLog does in the anomaly detection. We don’t have enough training logs for LSTM either. This is different from DeepLog.
Classical Machine Learning w/ event counting (Current approach) will search the typical log events in KB firstly. Give them big weights (More attention). Then take acount for logs in contexts and give them small weights (Less attention).
Classical ML doesn’t care the word order, so are much less affected by surrounding context uncertainties. Also, for prediction, no need know sessions / segmentations in advance. Few training logs will work well too.

Feature Extraction
Overview
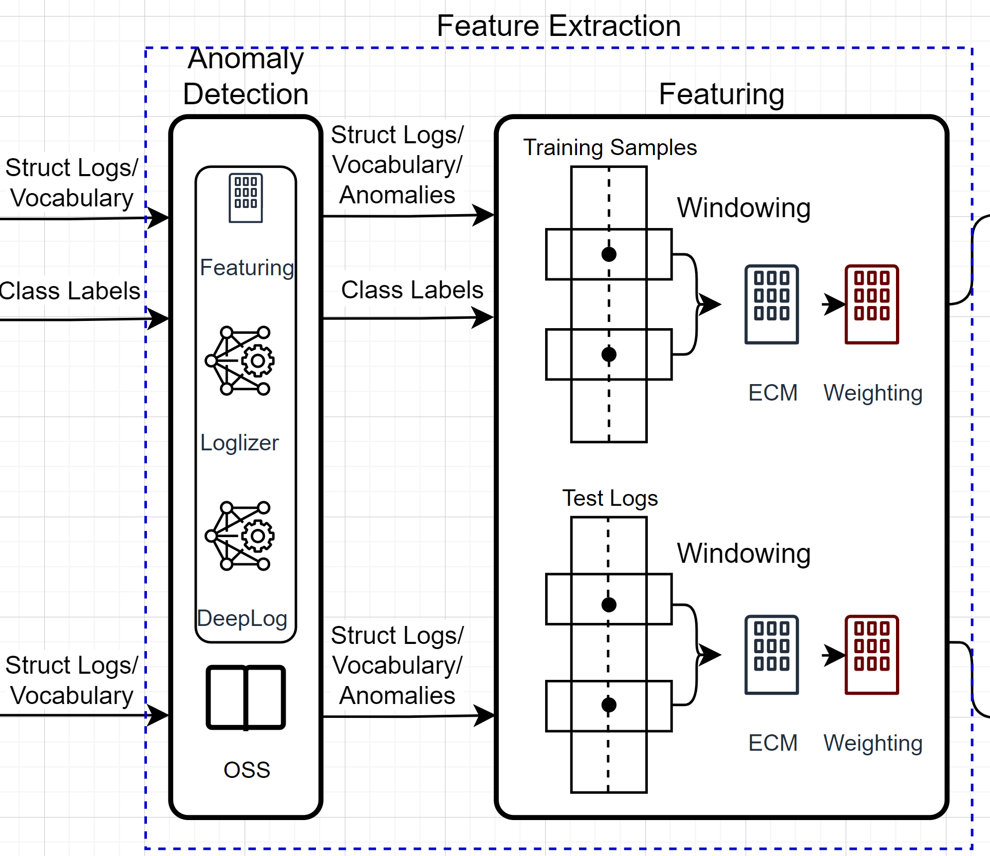
1) The OSS iterates each log and retrieve it in the KB.
2) If hit, label this log and count it. At the same time, label / count the other logs in the window.
3) Compute the frequency of typical logs and context logs at the end.
4) The weight of each log:
- weight = weight_type + log_freq / num_logs
- weight_type: Typical log has big value, while others in context have small value.
5) The TF-IDF is not used
- Training data maybe not enough
- Domain knowledge is used. More accurate.
Weights, contexts
1) We classified typical log events into categories of fatal/error/warning/notice and normal log events into info.
- Weight (main) of severities: typical (fatal: 3, error: 3, warning: 2, notice: 1), and normal (info: 1)
- High weights contribute more to the classification
- E.g. For CM logs, we set T3 event as warning, T4 as error, and MAC reset as fatal, etc.
2) Besides master weights, we also consider secondary weights.
- Calculate the frequency of event.
- Schemes
- FULL: Use full document to calc frequency
- PART: Only consider logs swept by windowing
3) Some typical events should not take context/window into account. Add option of having no context for typical log events.
- E.g. The nonvol writing failure event may repeat for some time being irrespective of the context. It’s not reasonable to count context for this kind of typical log events.
Combating curse of dimensionality
When feature dimension is high, overfitting will happen. Increasing training data set can relieve it to some extent, but it is not realistic usually.
- https://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
Unfortunately our feature dimension is very high (e.g. 2000), and training samples are very few (e.g. min 4~5 samples per target class).
Our strategy:
Typical events from knowledge base help filter noises. Predefined weights give the typical events more attention for a target class.
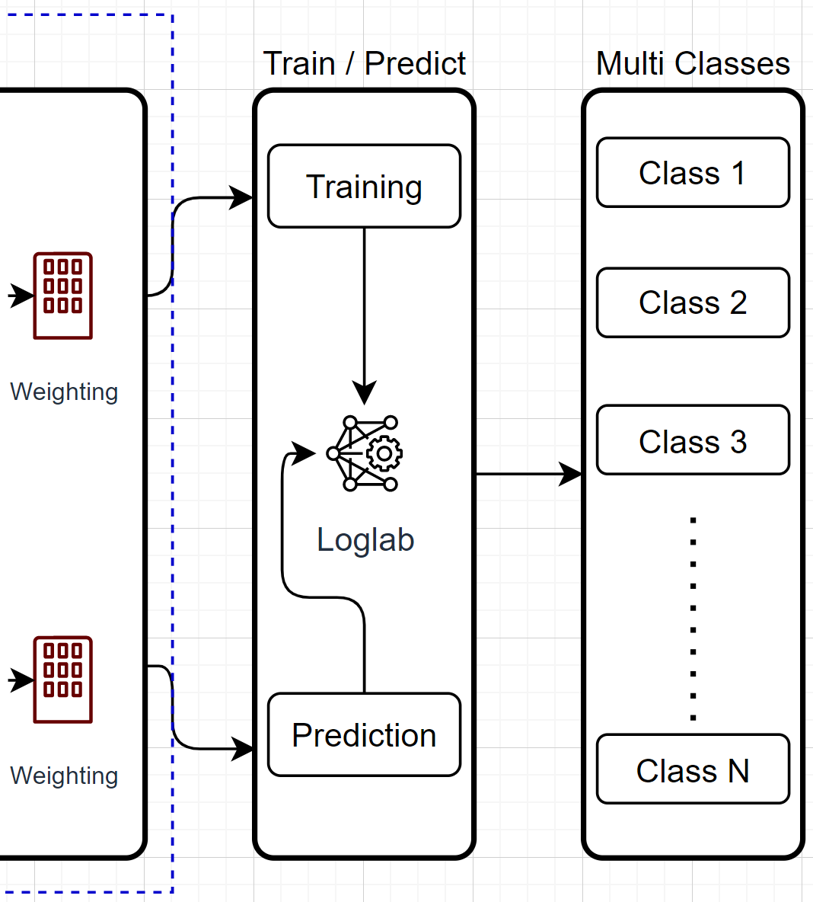
Models Training and Deployment
We use the sklearn library to train three models
- Random Forrest
- Logistic Regression
- SVM
Other classical models can also be tried easily.
The trained models are stored as binary format w/ the help of onnxruntime. When doing prediction, load back the onnx binary into memory.
Miscellaneous
Timestamp Width Learning
The timestamp format in log files for prediction is unknown or doesn’t exist. We don’t expect human to intervene. With the help of template library, we can learn the width of timestamp without knowning it in advance.

Recovering of Entangled / Broken Lines
Log from thread with low priority might be broken by high priority threads when printing to the same stdout console. Some of them can be recovered automatically.
In the example below, “Logging event: …” is broken. We can recover it automatically with the help of template library.
